
Read the full article on DataCamp: Gemma 3n – A Guide With Demo Project
Learn how to build an Android app that uses Google’s Gemma 3n to answer questions about images locally on your device—completely offline.
Overview
Gemma 3n is a compact, multimodal model developed by Google AI Edge, optimized for vision-language tasks directly on edge devices like Android phones. This tutorial walks you through how to build and run an offline Android app powered by Gemma 3n, enabling users to:
- Ask natural language questions about images
- Run inference entirely offline using Google’s AI Edge LiteRT
- Deploy a lightweight and performant mobile app
What Is Gemma 3n?
Gemma 3n is part of Google’s family of open-weight models for edge deployment. It supports text, image, and audio modalities and is designed to run efficiently on devices with limited compute.
Key Features:
- Multimodal input: Text + Image input for grounded visual reasoning
- Edge deployment: Offline inference with AI Edge LiteRT
- Efficient inference: Selective activation + MatFormer + PLE caching
- Mobile optimized: Supports FP16/INT4 inference on CPU/GPU/NPU
- Open source & commercial-ready: Available via Google AI Edge Gallery
How to Access Gemma 3n
You can access the model using:
- Google AI Studio (browser)
- Hugging Face
.taskfile for local runtime - Google’s Gallery App for Android (recommended)
Step-by-Step Implementation
Step 1: Clone and Set Up the App
- Create a new Empty Activity in Android Studio.
- Clone Google’s official Gallery repo:
git clone https://github.com/google-ai-edge/gallery
cd gallery/android
- Open it in Android Studio and explore the files.
Step 2: Prune All Tasks Except Ask Image
Edit the Tasks.kt file:
val TASKS: List<Task> = listOf(
TASK_LLM_ASK_IMAGE
)
This removes other demo screens like Chat or Prompt Lab.
Step 3: Auto-Navigate to the Ask Image Screen
Update GalleryApp.kt to auto-launch the Ask Image screen:
LaunchedEffect(Unit) {
TASK_LLM_ASK_IMAGE.models.firstOrNull()?.name?.let { modelName ->
navController.navigate("${LlmAskImageDestination.route}/$modelName") {
popUpTo("home") { inclusive = true }
}
}
}
Step 4: Install and Run the App on Your Device
Step 4.1: Enable Wireless Debugging
- Turn on Developer Options and Wireless Debugging in Android settings.
Step 4.2: Pair Device in Android Studio
- Open Device Manager → Pair via QR Code → Scan with phone.
Step 4.3: Run and Mirror
- Start device mirroring.
- Hit the green Run icon to deploy app.
Step 4.4: Download the Model On-Device
- Login to Hugging Face in the opened browser.
- Download the model (e.g.,
gemma-3n-e2b-it-int4.task).
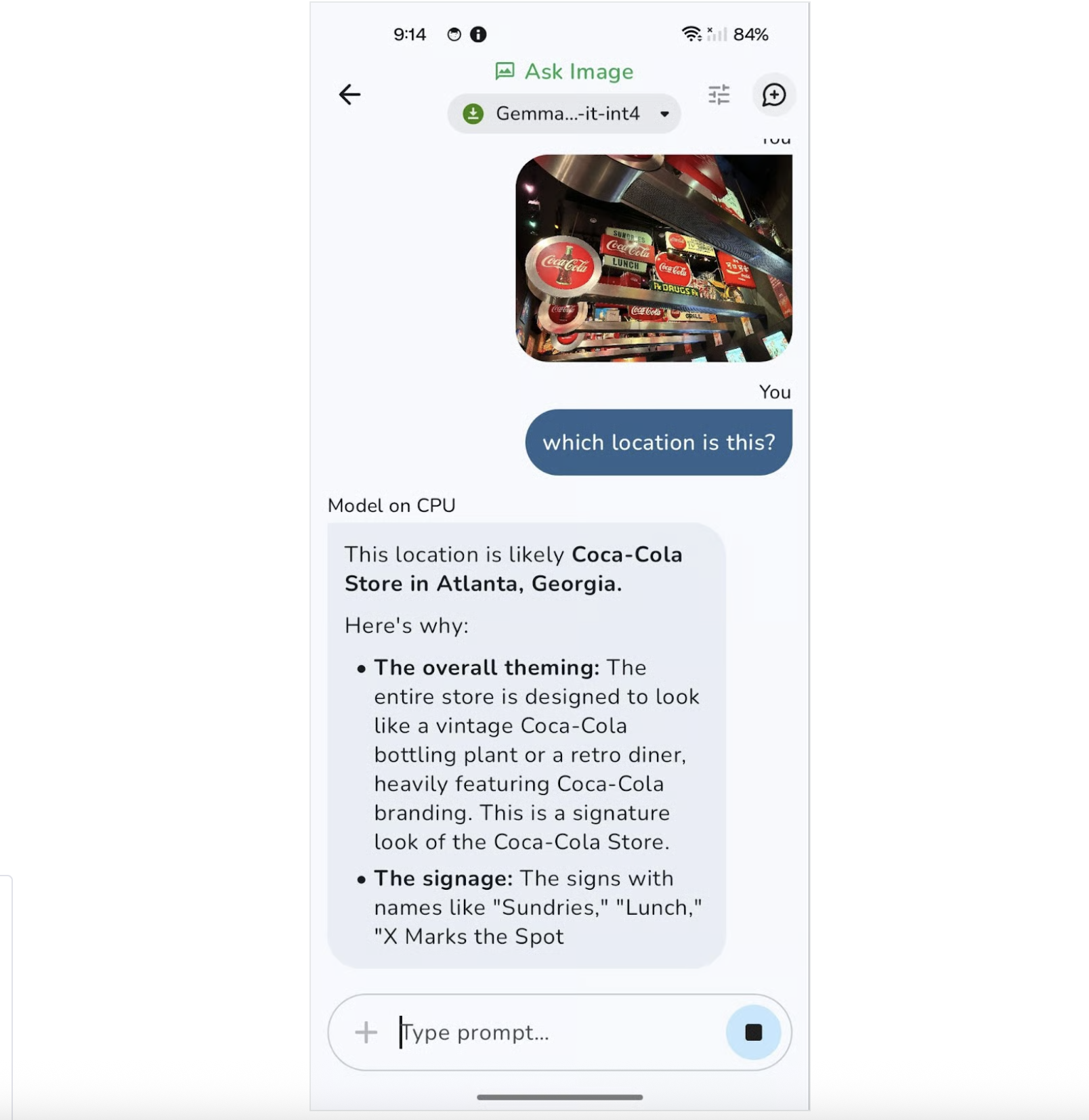
Step 4.5: Ask Questions About Images
- Take a photo or select from gallery.
- Enter your question (e.g., “What is this food?”).
- Choose CPU or GPU execution via the Tune icon.
Performance Tips
- CPU: Better prefill speed
- GPU: Faster decoding and overall lower latency
- For larger images or complex prompts, GPU is preferred.
Demo Project
Explore the code and setup in the official project repository:
GitHub: Gemma 3n Android App Demo
Conclusion
Gemma 3n enables fast, private, and offline vision-language reasoning on edge devices. This guide walked you through setting up a working Android app that lets you interact with images and ask natural language questions using an embedded AI model—no internet required.
As Google’s MatFormer architecture matures, expect even smaller, faster, and smarter multimodal agents for mobile, health, and education use cases.
More Edge AI Tutorials:
Comments