
Read the full article on DataCamp: How to Set Up and Run Qwen 3 Locally With Ollama
Learn how to install, set up, and, run Qwen3 locally with Ollama, and build a simple Gradio-based reasoning and translation app.
Why Run Qwen3 Locally?
Running Qwen3 locally provides major benefits:
- Privacy: No data leaves your machine.
- Latency: Fast inference without API calls.
- Cost-efficiency: Avoids cloud usage fees.
- Control: Customize model usage and prompts.
- Offline access: Use Qwen3 anywhere, once downloaded.
Qwen3 is optimized for both deep reasoning (via /think) and fast decoding (/no_think), making it ideal for local experimentation and deployment.
Setting Up Qwen3 Locally With Ollama
Step 1: Install Ollama
Download from ollama.com/download and install for your OS. Then verify:
ollama --version
Step 2: Download and Run Qwen3
Run the default model:
ollama run qwen3
Or use a smaller one for lower resource use:
ollama run qwen3:4b
Qwen3 Model Reference Table
| Model | Command | Best For |
|---|---|---|
| Qwen3-0.6B | ollama run qwen3:0.6b |
Edge devices, mobile |
| Qwen3-1.7B | ollama run qwen3:1.7b |
Chatbots, assistants |
| Qwen3-4B | ollama run qwen3:4b |
General tasks |
| Qwen3-8B | ollama run qwen3:8b |
Multilingual and reasoning |
| Qwen3-14B | ollama run qwen3:14b |
Content creation, problem solving |
| Qwen3-32B | ollama run qwen3:32b |
Context-rich tasks |
| Qwen3-30B-A3B (MoE) | ollama run qwen3:30b-a3b |
Efficient coding inference |
| Qwen3-235B-A22B (MoE) | ollama run qwen3:235b-a22b |
Enterprise-grade reasoning |
Step 3: Serve Qwen3 via API
ollama serve
This exposes the API at http://localhost:11434.
Using Qwen3 Locally
Option 1: CLI Inference
echo "What is the capital of Brazil? /think" | ollama run qwen3:8b
Option 2: Local API
curl http://localhost:11434/api/chat -d '{
"model": "qwen3:8b",
"messages": [{"role": "user", "content": "Define entropy in physics. /think"}],
"stream": false
}'
Option 3: Python API
import ollama
response = ollama.chat(
model="qwen3:8b",
messages=[{"role": "user", "content": "Summarize the theory of evolution. /think"}]
)
print(response["message"]["content"])
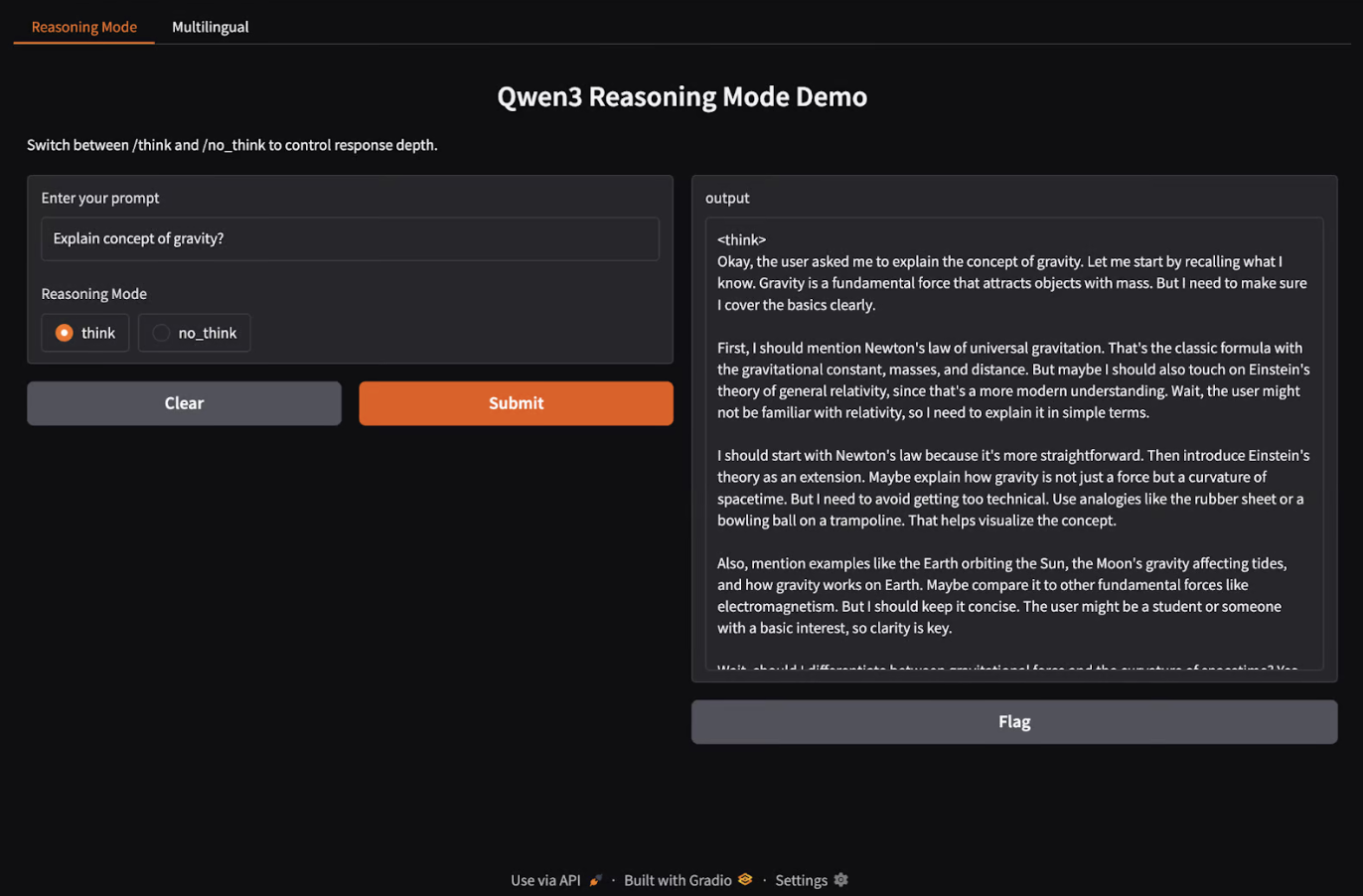
Building a Local Reasoning App With Qwen3
Step 1: Hybrid Reasoning App (Gradio)
import gradio as gr
import subprocess
def reasoning_qwen3(prompt, mode):
prompt_with_mode = f"{prompt} /{mode}"
result = subprocess.run(
["ollama", "run", "qwen3:8b"],
input=prompt_with_mode.encode(),
stdout=subprocess.PIPE
)
return result.stdout.decode()
reasoning_ui = gr.Interface(
fn=reasoning_qwen3,
inputs=[
gr.Textbox(label="Enter your prompt"),
gr.Radio(["think", "no_think"], label="Reasoning Mode", value="think")
],
outputs="text",
title="Qwen3 Reasoning Mode Demo",
description="Switch between /think and /no_think to control response depth."
)
Step 2: Multilingual Translator Tab
def multilingual_qwen3(prompt, lang):
if lang != "English":
prompt = f"Translate to {lang}: {prompt}"
result = subprocess.run(
["ollama", "run", "qwen3:8b"],
input=prompt.encode(),
stdout=subprocess.PIPE
)
return result.stdout.decode()
multilingual_ui = gr.Interface(
fn=multilingual_qwen3,
inputs=[
gr.Textbox(label="Enter your prompt"),
gr.Dropdown(["English", "French", "Hindi", "Chinese"], label="Target Language", value="English")
],
outputs="text",
title="Qwen3 Multilingual Translator",
description="Use Qwen3 locally to translate prompts to different languages."
)
Step 3: Combine Tabs and Launch
demo = gr.TabbedInterface(
[reasoning_ui, multilingual_ui],
tab_names=["Reasoning Mode", "Multilingual"]
)
demo.launch(debug=True)
Conclusion
With Qwen3 and Ollama, you can:
- Run powerful LLMs locally.
- Use hybrid reasoning with
/thinkand/no_think. - Build private, fast, and cost-free applications.
- Translate across 100+ languages.
To explore more:
Comments