
Read the full article on DataCamp: Run QwQ-32B locally with Ollama
Learn how to build intelligent assistants using Mistral Agents API and explore agent creation, tool usage, memory retention, and orchestration. A hands-on Nutrition Coach demo ties it all together.
How to Set Up and Run QwQ 32B Locally With Ollama
Learn how to install, set up, and run QwQ-32B locally with Ollama and build a simple Gradio application.
Mar 10, 2025 · 12 min read
Contents
- Why Run QwQ-32B Locally?
- Setting Up QwQ-32B Locally With Ollama
- Using QwQ-32B Locally
- Running a Logical Reasoning App With QwQ-32B Locally
- Conclusion
Why Run QwQ-32B Locally?
Despite its size, QwQ-32B can be quantized to run efficiently on consumer hardware. Running QwQ-32B locally gives you complete control over model execution without dependency on external servers.
Advantages:
- Privacy & security
- Uninterrupted access
- Faster performance
- More customization
- Cost efficiency
- Offline availability
Setting Up QwQ-32B Locally With Ollama
Step 1: Install Ollama
Download and install from Ollama’s official website.
Step 2: Download and Run QwQ-32B
ollama run qwq:32b
Or use the quantized version:
ollama run qwq:Q4_K_M
Step 3: Serve QwQ-32B in the Background
ollama serve
Using QwQ-32B Locally
Step 1: Inference via CLI
ollama run qwq
Then type a prompt like:
How many r's are in the word "strawberry”?
Step 2: Using Ollama API
curl -X POST http://localhost:11434/api/chat -H "Content-Type: application/json" -d '{
"model": "qwq",
"messages": [{"role": "user", "content": "Explain Newton second law of motion"}],
"stream": false
}'
Step 3: Using Python
Install the Ollama package:
pip install ollama
Then run:
import ollama
response = ollama.chat(
model="qwq",
messages=[{"role": "user", "content": "Explain Newton's second law of motion"}],
)
print(response["message"]["content"])
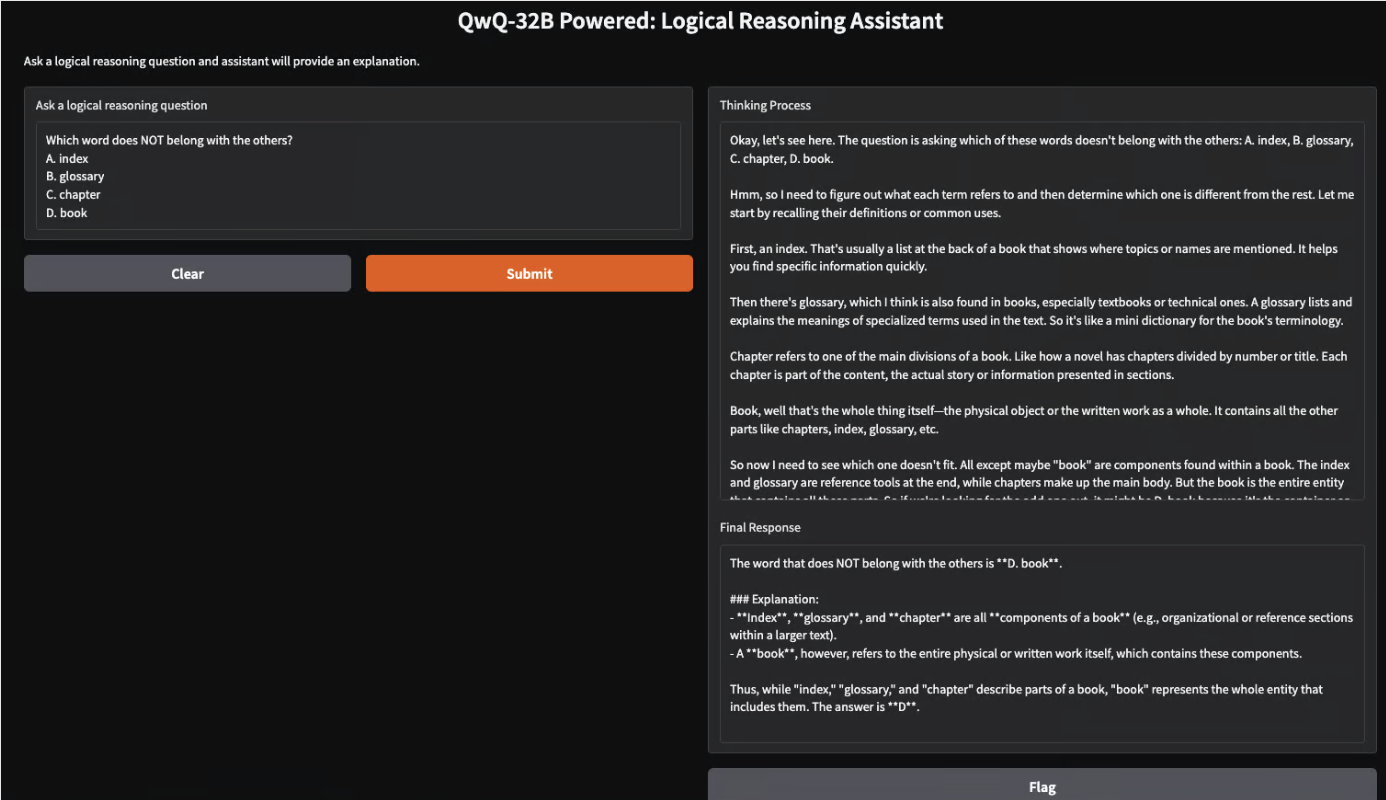
Running a Logical Reasoning App With QwQ-32B Locally
Step 1: Prerequisites
pip install gradio ollama
Step 2: Query Function
import ollama
import re
def query_qwq(question):
response = ollama.chat(
model="qwq",
messages=[{"role": "user", "content": question}]
)
full_response = response["message"]["content"]
think_match = re.search(r"<think>(.*?)</think>", full_response, re.DOTALL)
think_text = think_match.group(1).strip() if think_match else "Thinking process not explicitly provided."
final_response = re.sub(r"<think>.*?</think>", "", full_response, flags=re.DOTALL).strip()
return think_text, final_response
Step 3: Gradio Interface
import gradio as gr
interface = gr.Interface(
fn=query_qwq,
inputs=gr.Textbox(label="Ask a logical reasoning question"),
outputs=[gr.Textbox(label="Thinking Process"), gr.Textbox(label="Final Response")],
title="QwQ-32B Powered: Logical Reasoning Assistant",
description="Ask a logical reasoning question and the assistant will provide an explanation."
)
interface.launch(debug=True)
Conclusion
Running QwQ-32B locally with Ollama enables private, fast, and cost-effective model inference. With this tutorial, you can explore its advanced reasoning capabilities in real time for tutoring, problem-solving, and logic-based apps.
Read the full tutorial at: DataCamp Blog
Comments